音频大模型评测Bench:AIR-Bench(ACL 2024)
2025-02-12
作者:杨千
我们的AIR-Bench是第一个关于音频理解大模型全面评估的Benchmark,在音频大模型迈向gpt4o的时代,相信AIR-Bench可以帮助大家更好的评估音频大模型,我们也希望我们的工作可以启发之后的音频大模型评估工作。
首先简单介绍一下背景,以往全面评估音频相关模型的benchmark,如SUPERB和HEAR,通过集成模型在各个标准TASK和标准数据集上的分数,以达到全面评估模型在各个任务上的表现能力。然而,随着大模型的兴起,被赋予音频能力的大模型,缺乏相映的Benchmark评测。通过各个标准数据集上的测试分数,无法反应模型在与人交互过程中的能力,因为标准数据集的分数更多的反映的是模型在特定任务,如语音识别等的能力,但大模型的与人类对齐的能力,这一直接影响用户交互体验的能力,无法通过各个标准数据集考量。最近唯一的评测音频大模型的Benchmark:Dynamic-SUPERB,专注于人类语音处理,并不涵盖开放式对话生成。因此,我们提出了第一个全面评估音频大模型的Benchmark:AIR-Bench。
首先我来介绍一下我们AIR-Bench的构成,AIR-Bench由两个子Benchmark构成,包括foundation和chat。
Foundation benchmark注重于从各个任务方面来测试音频大模型的性能,包括speech的任务如情绪识别,sound的任务如场景识别,music的任务如乐器识别等,每个任务都由其对应的标准学术数据集构成。为了统一测量结果和便捷用户使用,foundation将所有的评测整理成了选择题的形式,并要求音频大模型判断选项,这样的方式统一了WER、ACC等指标,简化了音频大模型的评测过程。比如在情绪识别中,我们的question是What’s the dominant emotion expressed in the speech?,然后会给出 A.neutral B. angry C.sad D.happy四个选项。模型的prompt会要求模型直接返回选项。
而Chat benchmark注重于直接评测模型的free chat能力,Chat按照音频的类型分为了Speech、Sound、Music、Mixed-Audio。同样的一个简单的关于chat-benchmark的例子是:What phrase is repeated by the speaker at the beginning of the speech? Chat benchmark设计了各种简单或复杂的问题来模拟用户的日常交互,音频大模型返回其回答,对回答的评分由接下来的自动化评测方案完成。
那我来介绍一下AIR-Bench的自动化评测方案,这套自动化评测方案利用最先进的LLM如GPT-4进行评测,略过了人工评测的困难。具体来讲,无论是foundation还是chat benchmark,都会有一个“标准答案”,foundation是这个问题的正确答案选项,这是绝对的标准答案,而chat则是由GPT-4根据音频的meta信息,也就是标注过的音频元信息来生成的不标准的标准答案,这其实是一个基准,强大的LLM在打分的时候会打出两个分数:一个是reference答案也就是标准答案的分数,一个是音频大模型回答的分数。
Reference的存在维持了一个基准,使得强大的LLM对不同模型进行评测时能够相对无偏。这一套自动化评测的方案适用于任何大模型的评估,同时,更加强大的LLM的出世也会升级Evaluator,使评分更加无偏。
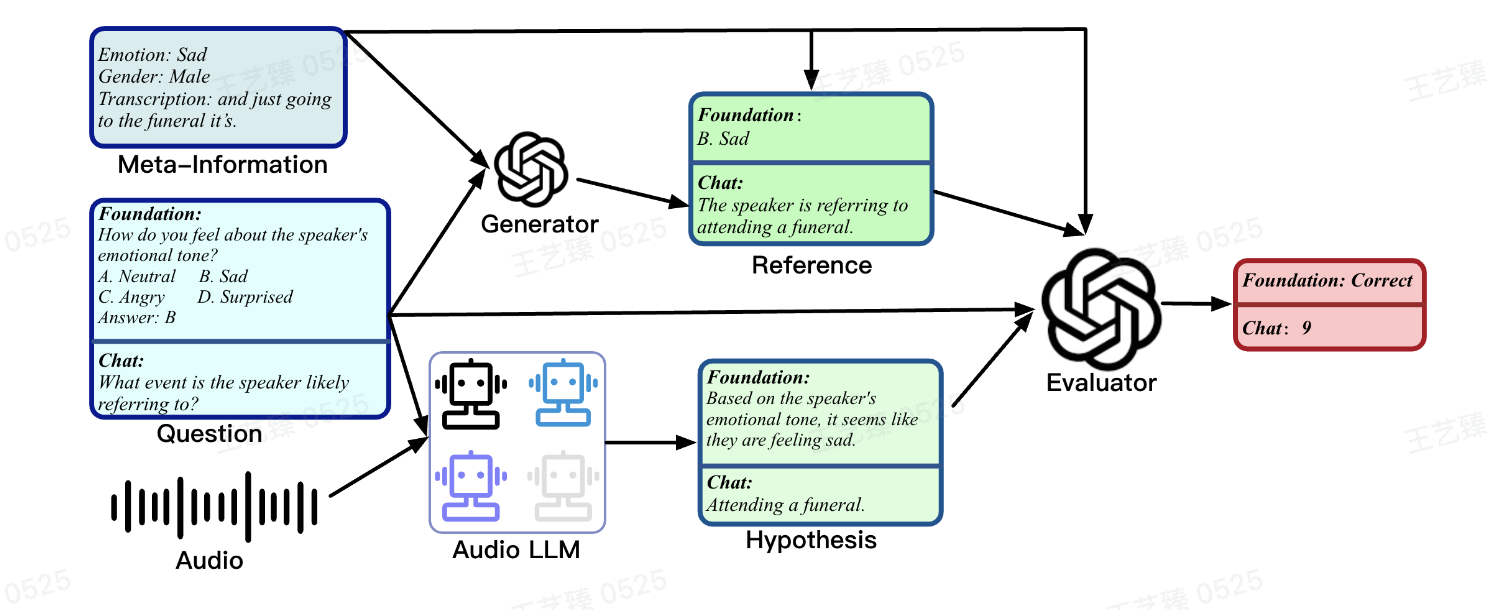
具体在这个图中,我们分开看一下Foundation和Chat。Foundation-bench的问题是How do you feel about the speaker's emotion tone?
待评测模型会给出一个回答,在图中就是hypothesis这里,虽然评测时prompt会要求待测模型返回指定选项名称,但是很多的Large Audio Language Model并不一定条条都能完全follow instruction,因此这些不能正确返回选项名称的情况,还需例如GPT-4通过Reference也就是正确选项判断待测模型是否在内容上回答正确,这个例子中待测模型成功回答了feeling sad,但是却没有选到B,我们在这种情况下依然判定其为正确,因为其内容回答的是正确的。
当然,我们在论文中也评测了指令评估的能力,这两部分我们在AIR-Bench中分开对待,这样很多模型的评测也会更加公平。再看一下Chat-Bench,Chat-Bench的问题是What event is the speaker likely referring to?待测模型给出回答:Attending a funeral;我们的Reference答案是The speaker is referring to attending a funeral;打分LLM如GPT-4其实会给出两个答案:分别对Reference进行判分和待测模型Hypothesis进行判分,图中为了避免误导只贴出了待测模型的分数9分(满分10分),这样自动化的打分就完成了。
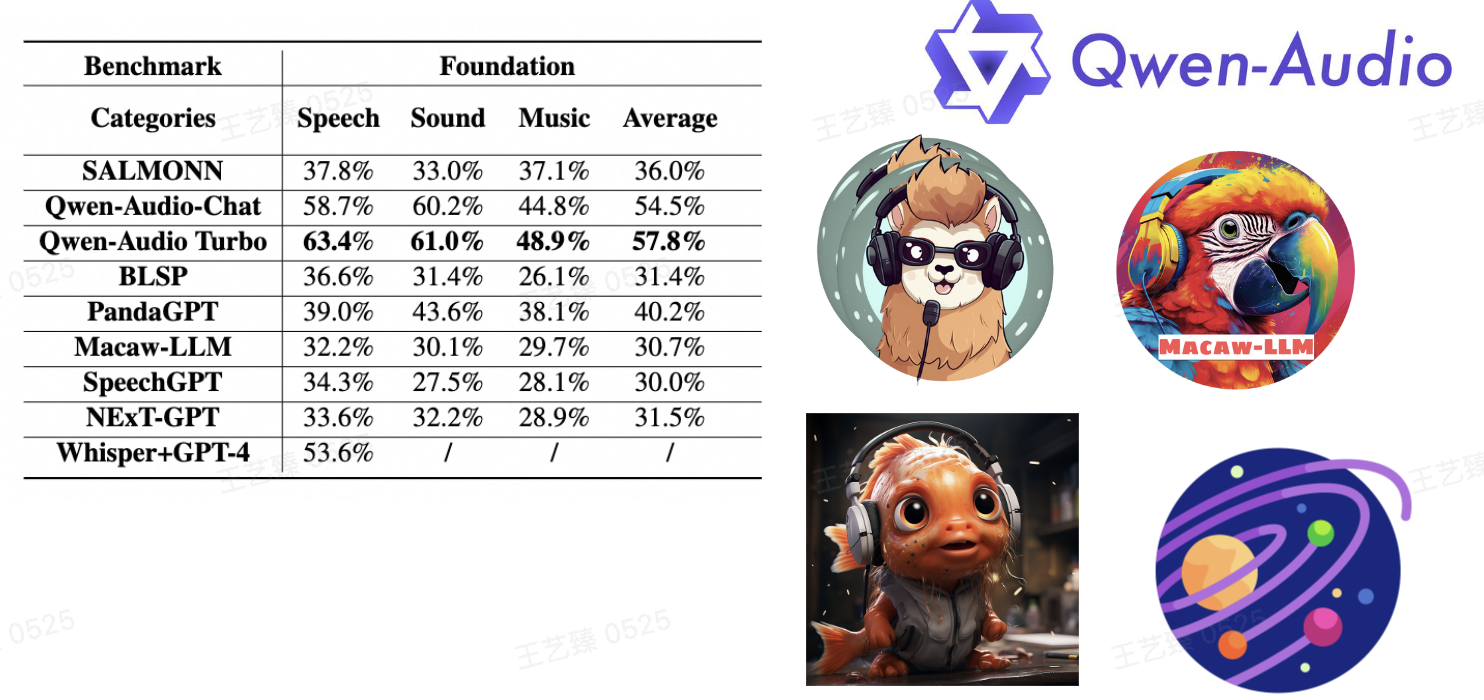
现在来看一下Large-Audio-Language-Model的评估结果,我们首先来看一下在Foundation-Benchmark上我们的评估结果,Qwen-Audio-Chat 和 Qwen-Audio Turbo 在Foundation benchmark中表现出色,在speech、sound和music上超越了其他模型。紧随这两个模型之后,PandaGPT 和 SALMONN 也表现出了不俗的表现。

接下来我们看一下Chat-Benchmark上的分数,Chat-Benchmark旨在评估音频大模型与人类进行真实交互时的表现。细心的朋友们已经发现了,这里多了Gemini-1.5-pro和Qwen2-Audio,因为这两个都是最近才开放测试的。Qwen2-Audio是通义千问系列多模态模型Qwen-Audio的续作,我们Qwen2-Audio的工作在今天早晨刚刚释出,他在speech、sound、music和mixed-audio上的表现都达到了SOTA,真正做到了多类型模态的音频理解,Speech理解能力达到了7分以上,比Gemini-1.5-pro还要高,大家感兴趣可以在arxiv上了解Qwen2-Audio的细节。
除了Qwen2-Audio以外,我们发现Gemini-1.5-pro具有很强的speech交互能力,但其sound和music能力逐步降低,在这份榜单中同样亮眼的还有SALMONN,虽然SALMONN的能力没有很突出,但是其speech、sound和music分数都达到了一个相对均衡且中等偏上的分数。
最后,对我们AIR-Bench的Insight做一总结:首先,整个AIR-Bench QA的构建与多模态大模型的SFT阶段Human-preference数据的构建很相似,能够启发多模态大模型的SFT数据集构建;其次,我们AIR-Bench的Evaluation Framework适用于所有的自动化评估;最后,我们AIR-Bench的评测数据集、评测代码已全面开源,camera-ready版本的论文将很快在ACL官方释出,同时将提供Github指引。当然大家有耐心也可以现在检索一下:OFA-SYS。