NeurIPS 2023 | 跨模态提示:微调大型预训 练模型适应音视频下游任务
2025-02-12
作者:段皞一
近年来,在音视频下游任务中部署大规模预训练模型已经取得了显著的成果。然而,这些模型主要是在单模态非受限数据集上进行训练的,仍然在多模态任务的特征提取方面面临挑战。这个局限性是因为在编码过程中引入了无关的模态特定信息,对下游任务的性能产生了不利影响。我们发表于 NeurIPS 2023的文章,《Cross-modal Prompts: Adapting Large Pre-trained Models for Audio-VisualDownstream Tasks》解决了这一挑战。
本文提出了一种新颖的双引导空间-通道-时间(DG-SCT)注意机制。该机制将音频和视觉模态作为软提示,基于当前多模态输入特征动态调整预训练模型的参数。具体来说,DG-SCT 模块将可训练的跨模态交互层整合到预训练的音频、视频编码器中,允许跨空间、通道和时间维度自适应地提取当前模态的关键信息,同时保留大规模预训练模型的冻结参数。

实验表明,我们提出的模型在多个下游任务中取得了 state-of-the-art,包括 AVE、AVVP、AVS 和AVQA 任务。此外,我们的模型在具有挑战性的 few-shot 和 zero-shot 场景中表现优越。此外,我们还进行了全面的实验:
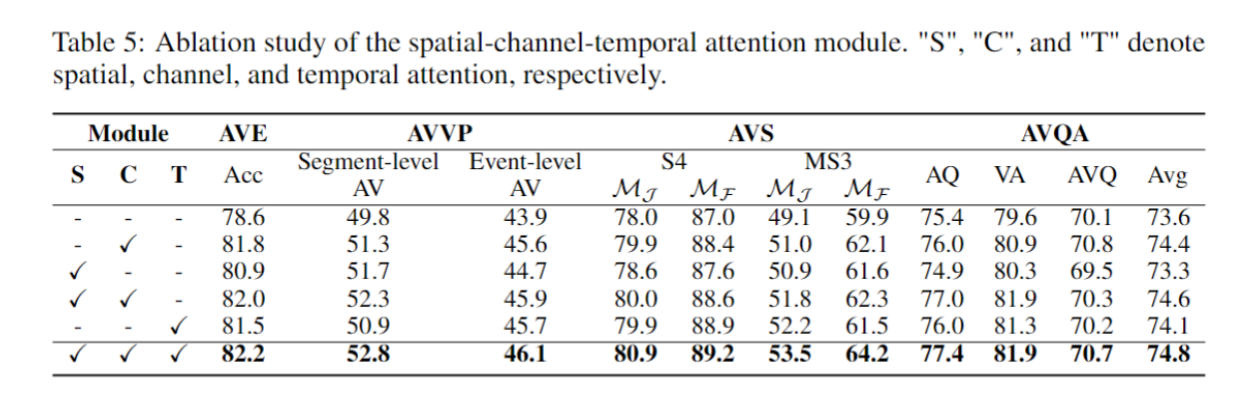
消融实验,验证了空间(S),通道(C)和时间(T)三个模块的有效性;
定性分析,可视化地分析模型对表征效果的提升;
性能分析,可训练参数和计算成本的比较。
总体来说,在 4 个数据集总共 25 个 setting 下,我们有 19 个取得了 sota 。我们的方法表现出了强大的泛化能力,并在未来的更多音视频场景中具有应用潜力。
项目介绍
随着 GPU 性能的不断提升,基于大规模数据进行预训练的模型在各种多模态任务中取得了显著的进展。然而,由于这些模型主要是在单一模态上进行预训练的,它们可能不太适用于当前的多模态下游任务。
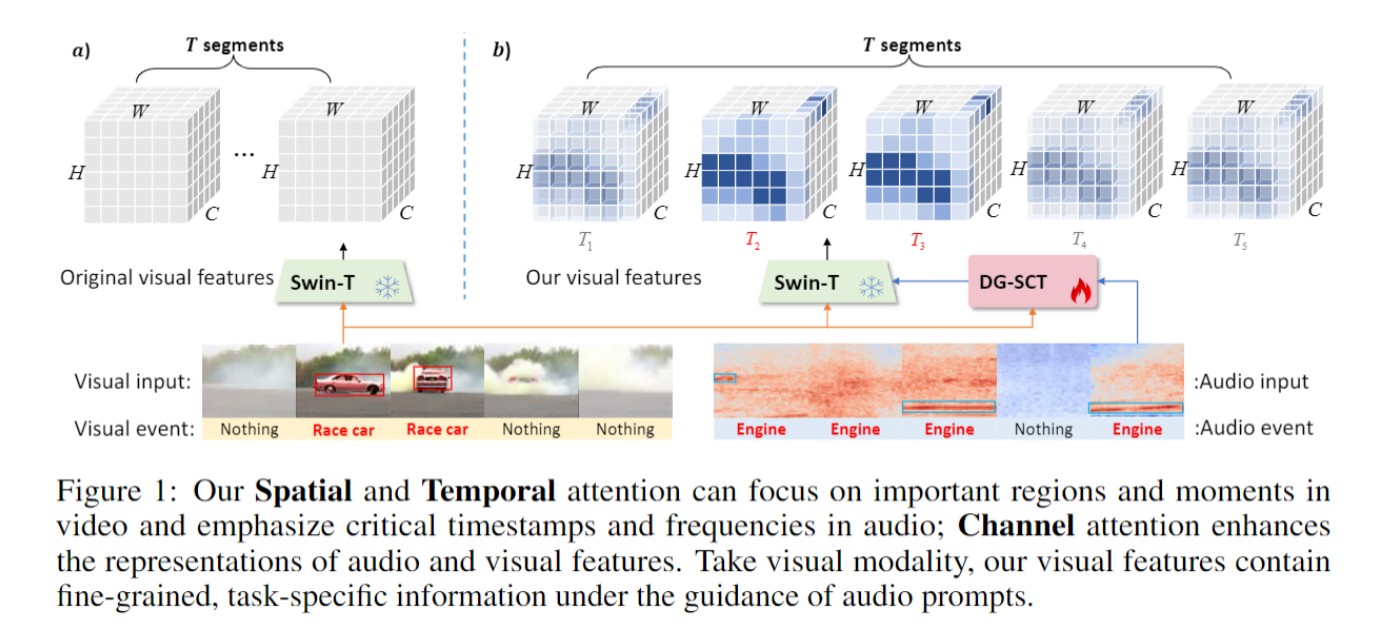
如 Figuire 1(a) 所示,预训练模型均匀地提取视觉特征并将它们直接传递给下游任务。然而,当感知到引擎声时,描述"汽车"的视觉区域应该比"树木"的区域更受关注。同时,当观察汽车时,应集中注意力于引擎的音频段。 因此,编码器不仅应该均匀提取当前模态的模态特定信息,还应该突出显示与其他模态相关的信息,以增强在下游任务中跨多样模态的特征融合。
音频或视频是否可以作为一种新颖的 prompt,以增强预训练模型对任务的理解并引导对应模态的自适应特征提取?答案是肯定的。
研究方法
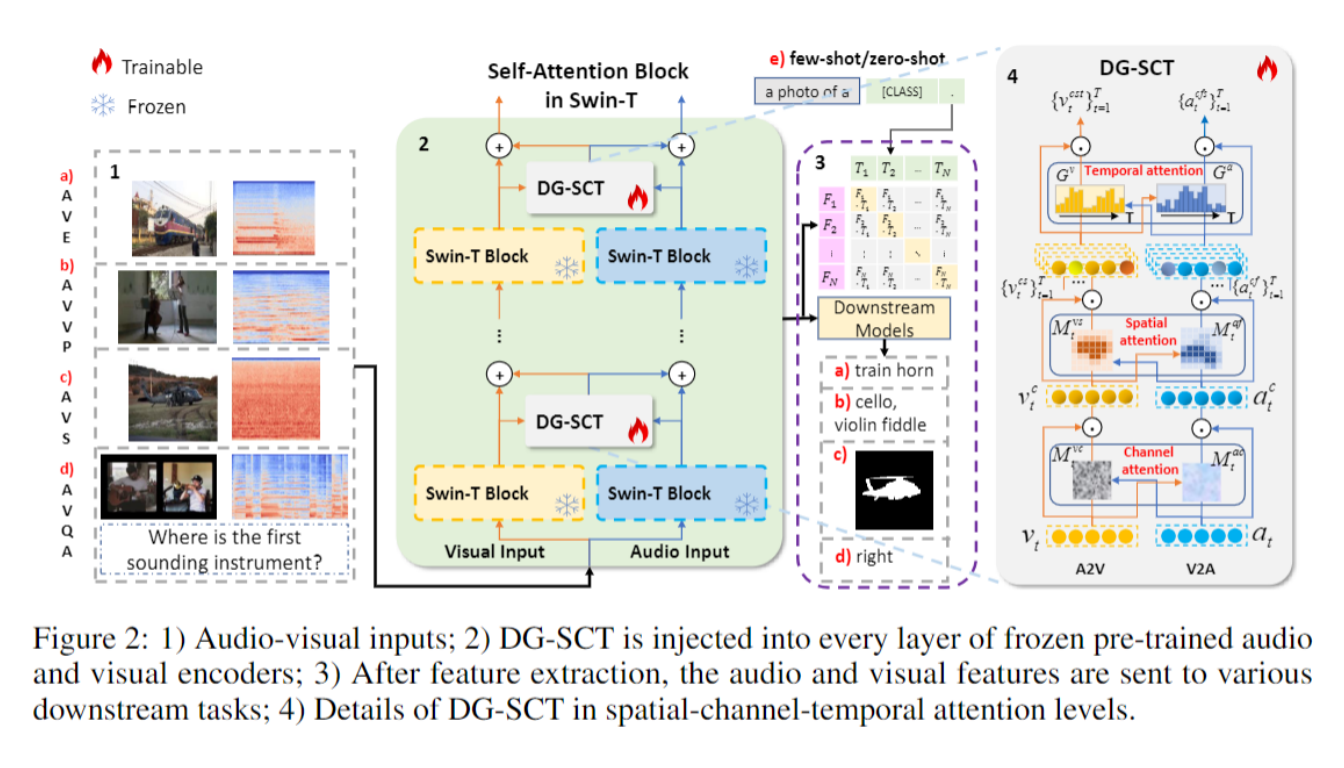
如 Figure 2 所示,DG-SCT 模块加入到音频、视频 Transformer 编码器的层间。也就是下面公式中的Ωa2v(α(ℓ),ν(ℓ) )和 Ωv2a(ν(ℓ),α(ℓ)):
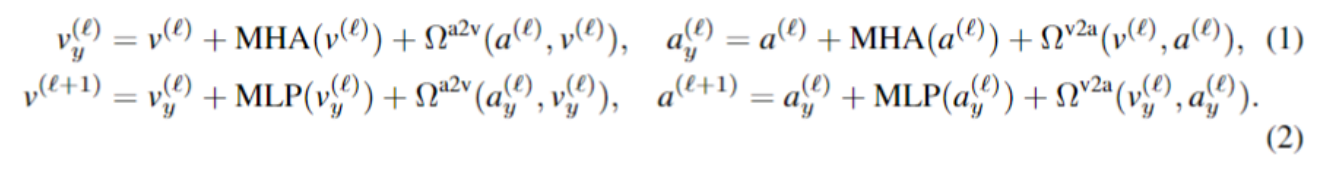
而 DG-SCT 模块中包含有 3 个子模块,按顺序依次为:
通道注意力机制(channel-wise attention)
不同的通道代表了特征的不同方面。引入通道注意力可以帮助模型忽略无关的特征,并提高表示的质量。我们让音频和视频作为相互引导的信号,分别得出 channel attention maps:Mtνc和Mtαc,明确地建模了它们之间的通道依赖关系。
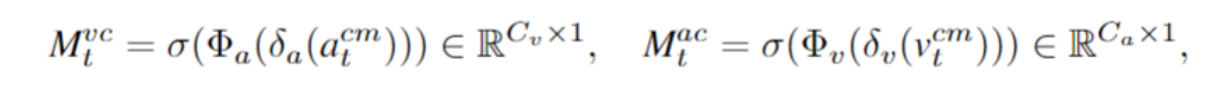
空间注意力机制(spatial-wise attention)
音频可以通过在空间维度上提供视觉关注来改善视觉特征提取。受此启发,我们利用音频和视觉提示的引导能力来分别引导视觉空间关注和音频频率关注。和通道注意力机制类似,我们得出 spatial attention maps:Mtνs和Mtαf。
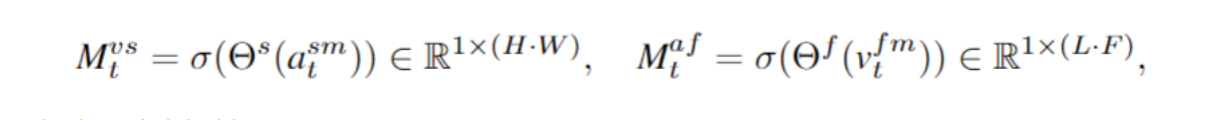
时间门注意力机制(temporal-gated attention)

最终,DG-SCT 将上述三个子模块得到的 attention maps/gates 融合: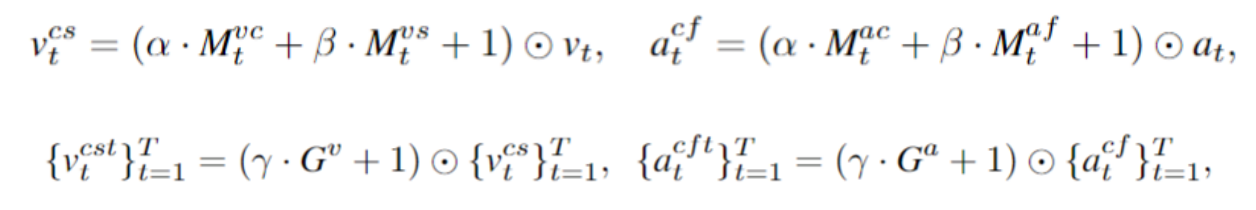
实验效果
任务描述
音频-视觉事件定位 (AVE) 在视频中的多个时间段内识别既可见又可听的音视频事件;
音频-视觉视频解析 (AVVP) 将视频解析为时间事件片段,并将其标记为可听、可见或两者皆有;
音频-视觉分割 (AVS) 输出在图像帧上产生声音的对象的 pixel-level map;
音频-视觉问答 (AVQA) 旨在根据对象和声音之间的关联来回答问题;
此外,我们在 AVE 和 LLP(AVVP 任务数据集) 数据集上提出了音频-视觉 few-shot/zero-shot 任务。在 AVE 数据集上评估 AVE 和分类任务,并在 LLP 数据集上进行分类任务。
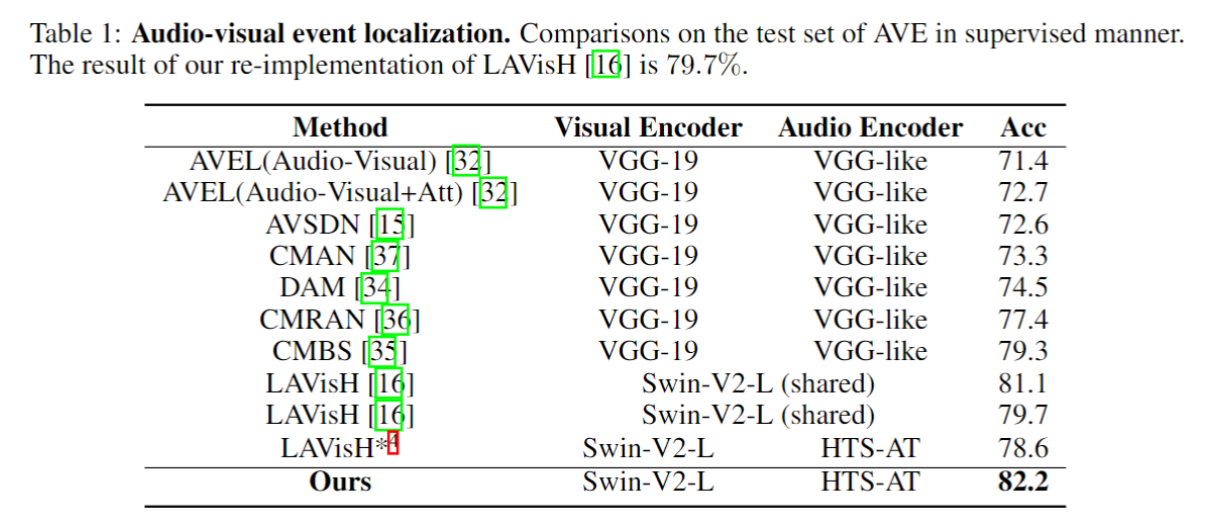
AVE
AVVP
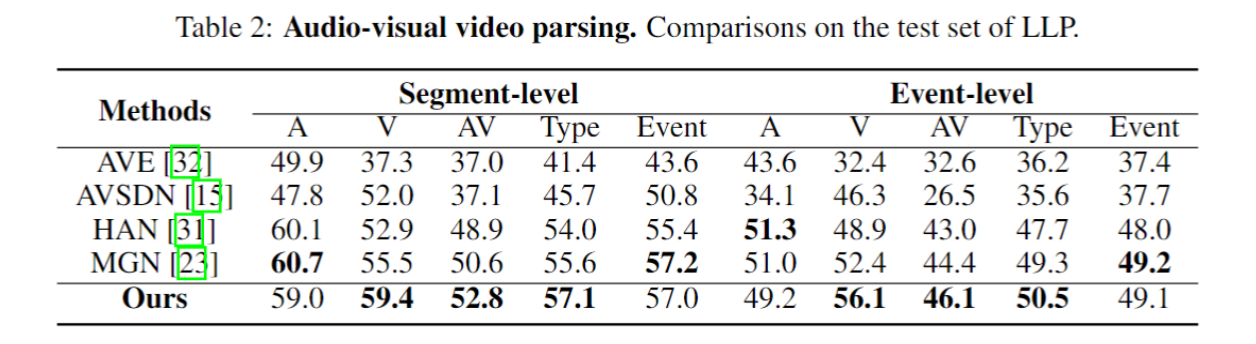
AVS
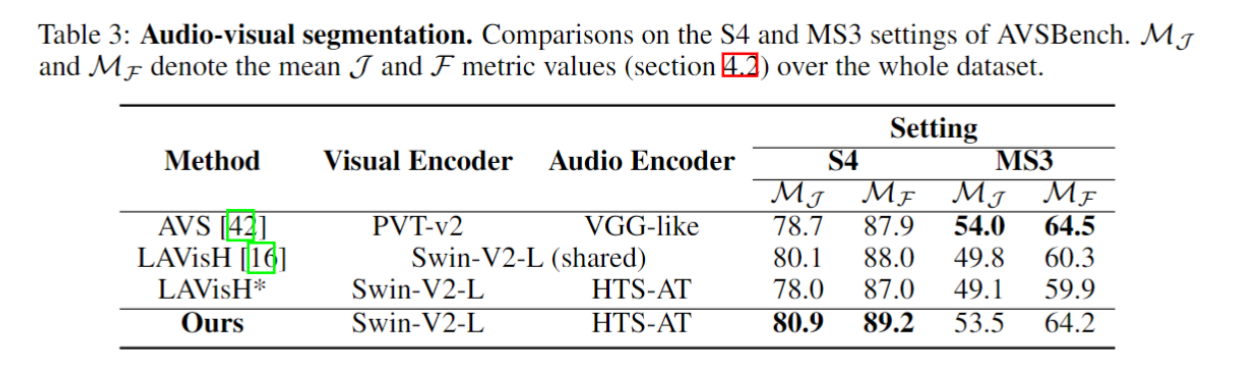
AVQA
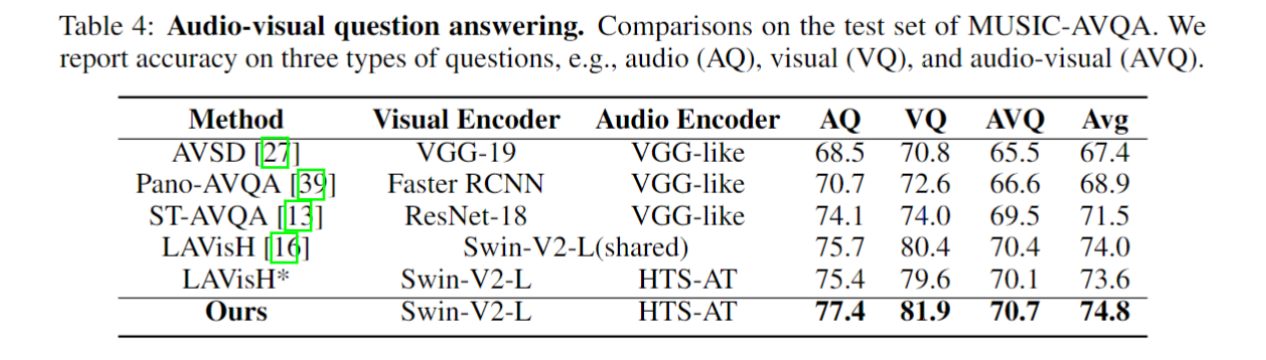
Few-shot/zero-shot
Ablation analysis
Qualitative analysis
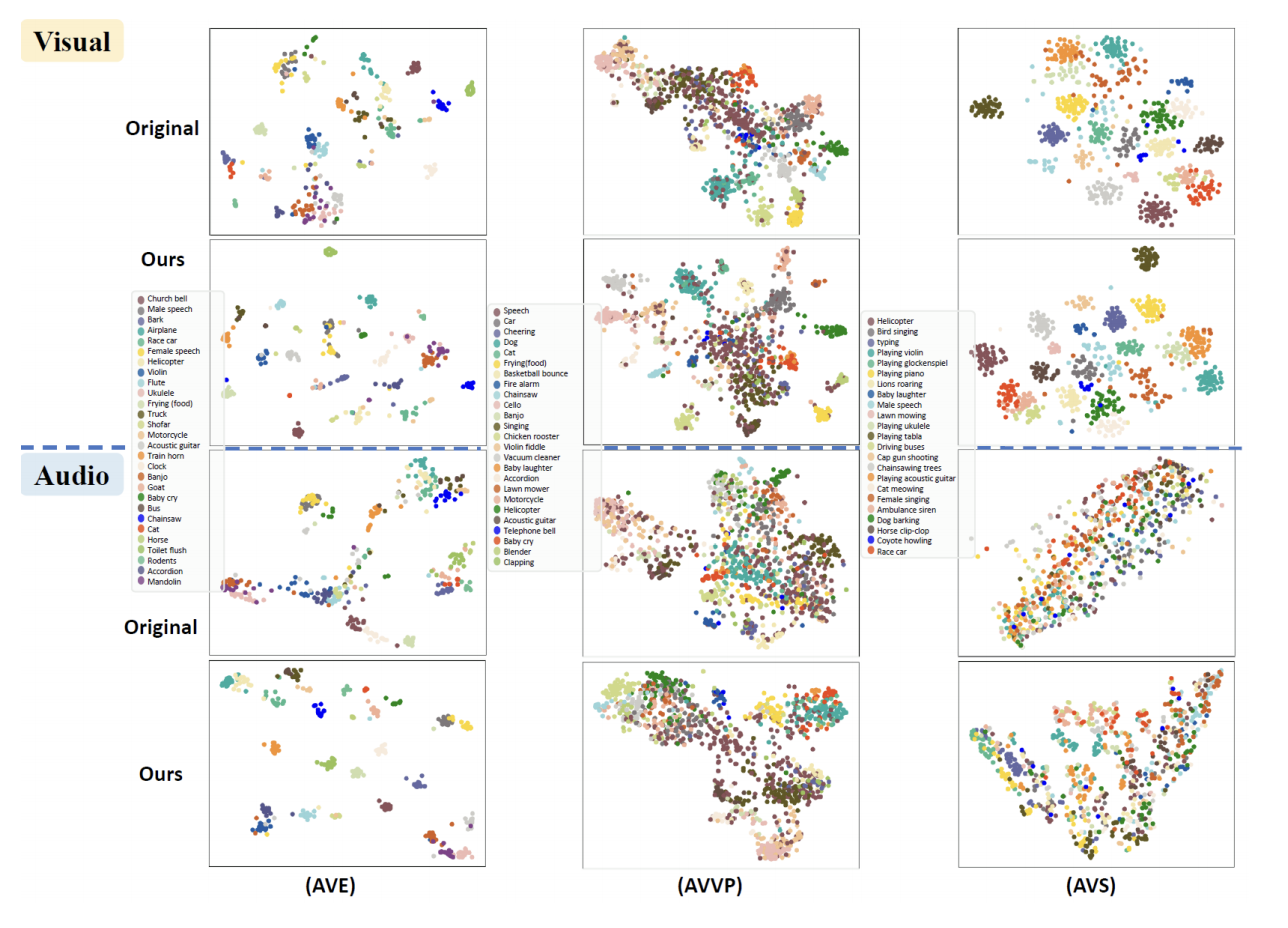
正如我们如下图所看到的,由提出的 DG-SCT 提取的特征在类内更加紧凑,而在类间更加分离。这表明,DG-SCT 模型成功地为不同下游任务中的每个模态学习了紧凑和具有区分性的特征。